原版的 deepin modelhub 内置的 llama.cpp 是没有开启 cuda 编译选项的,所以原版的 uos ai 没法调用 n 卡来跑模型的,就只能拿 CPU 算,速度比较慢
(原版的没有编译带 cuda 的 so)
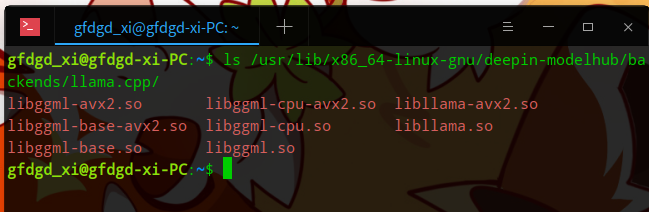
所以我手动开启了 cuda 选项重新编译了一下,就能用 N 卡算了
唯一的问题就是体积大了很多,安装包从原来的 2 MB 暴涨到了 77 MB
这是用 CPU 算的效果(AMD Ryzen 5700G + 2133 频率的内存)
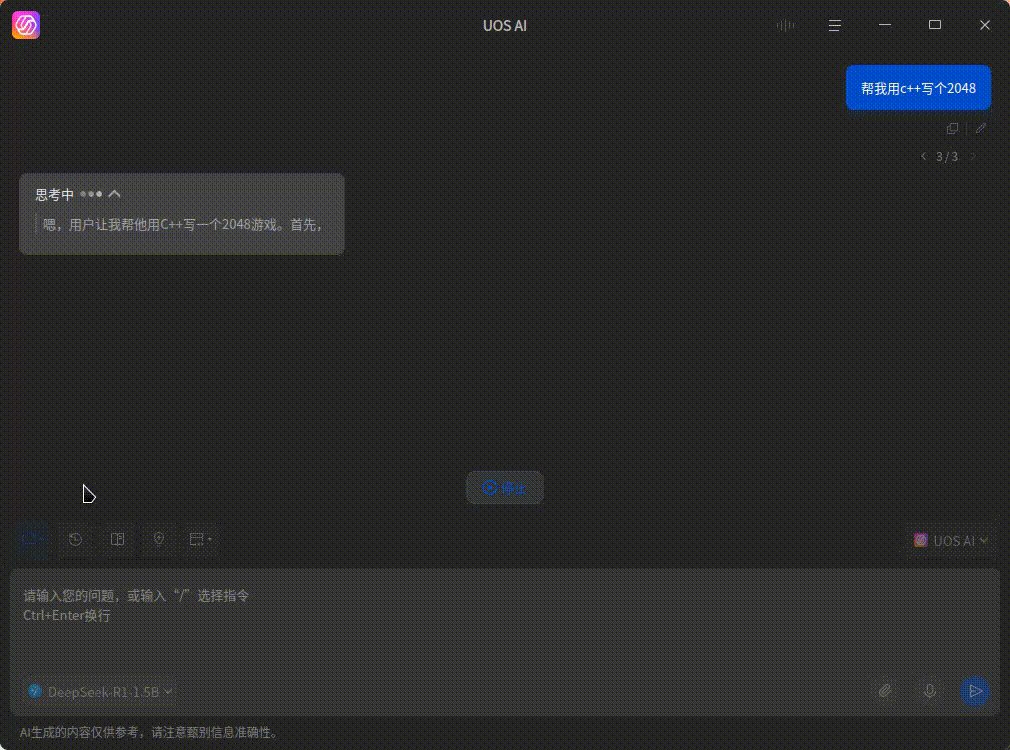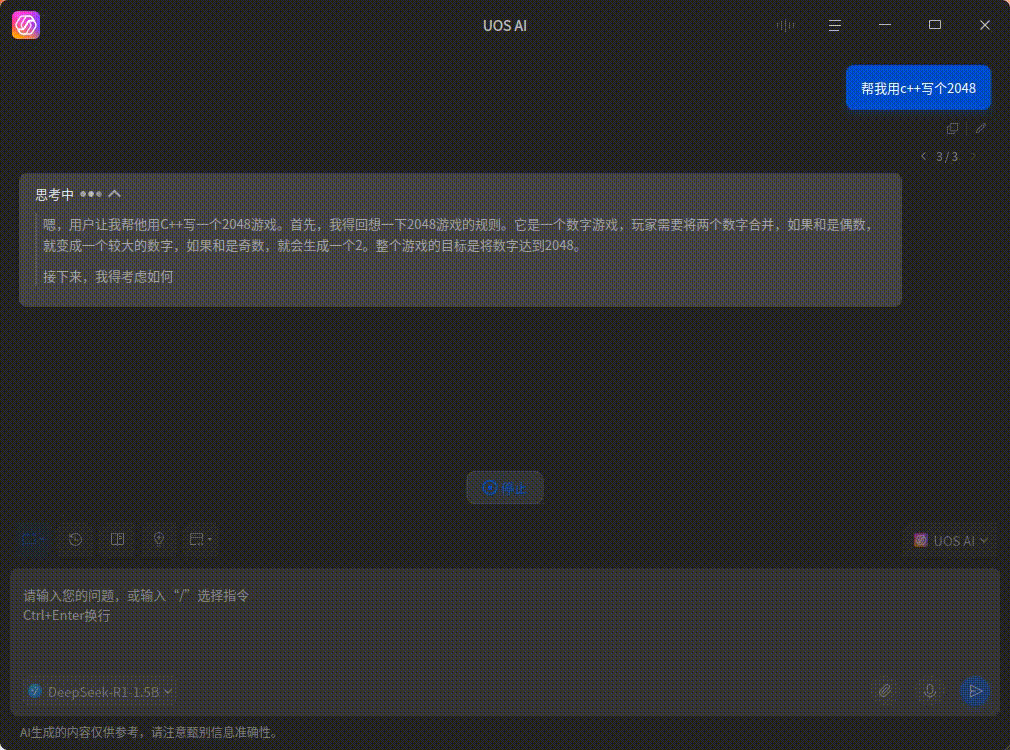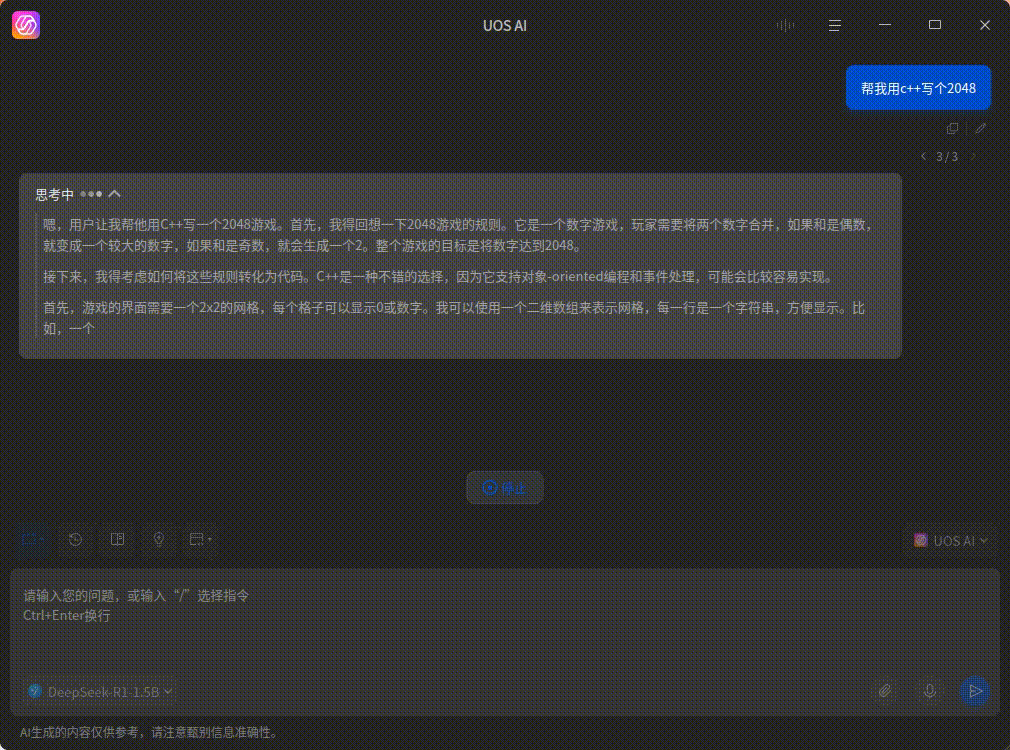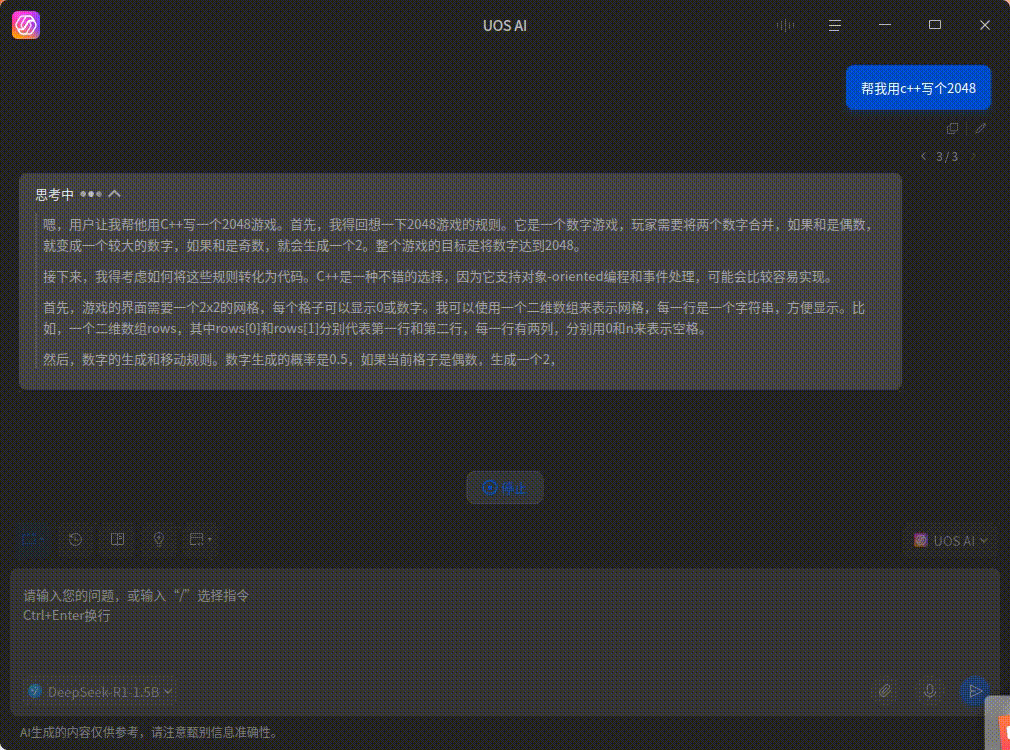
这个是 GPU 算的效果(4060ti 16G),会快很多
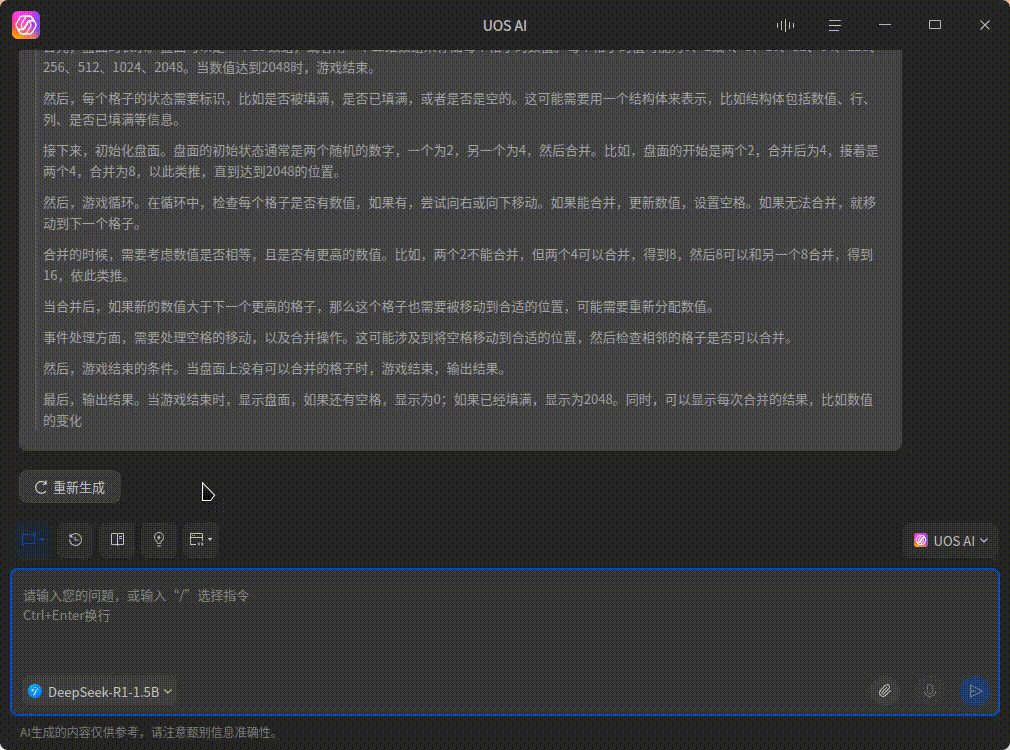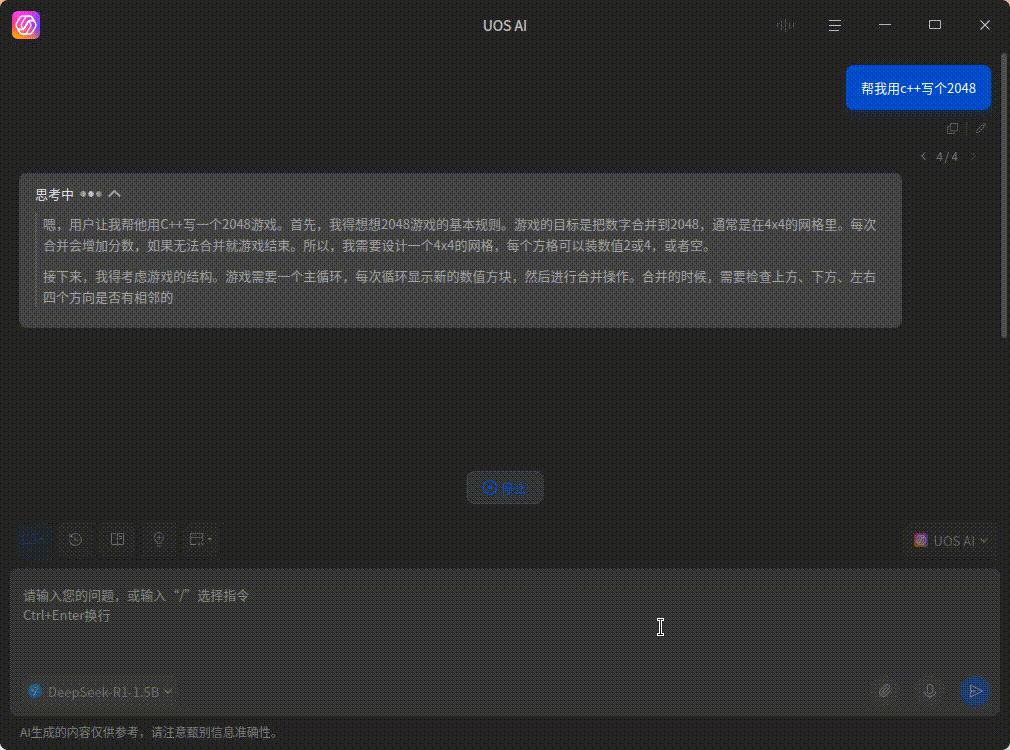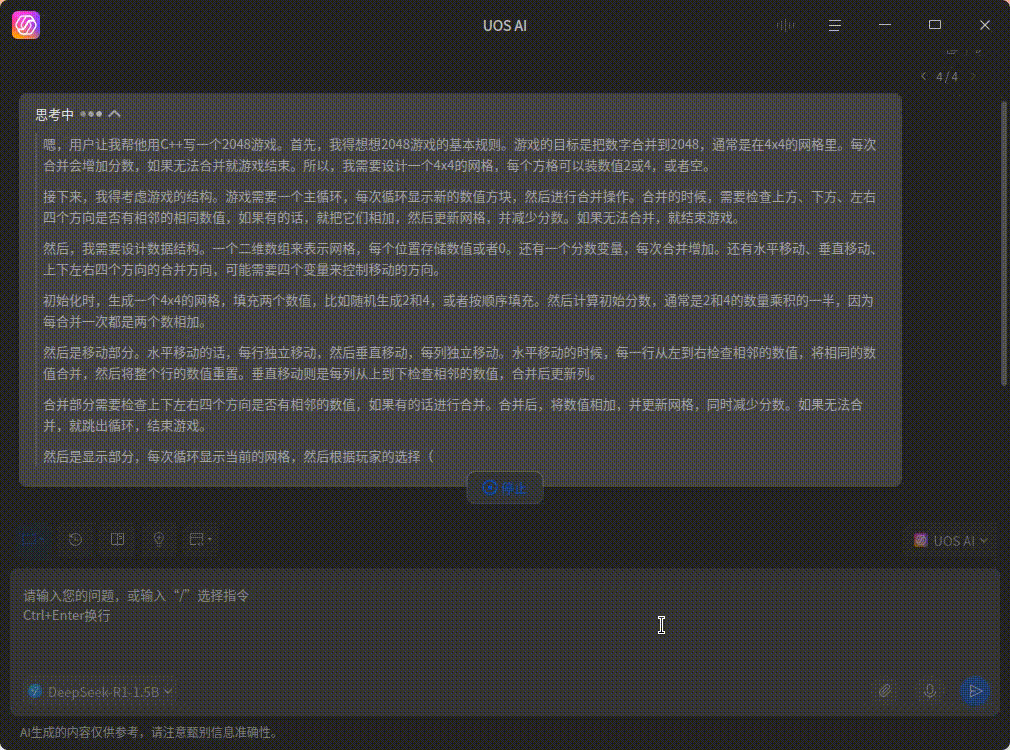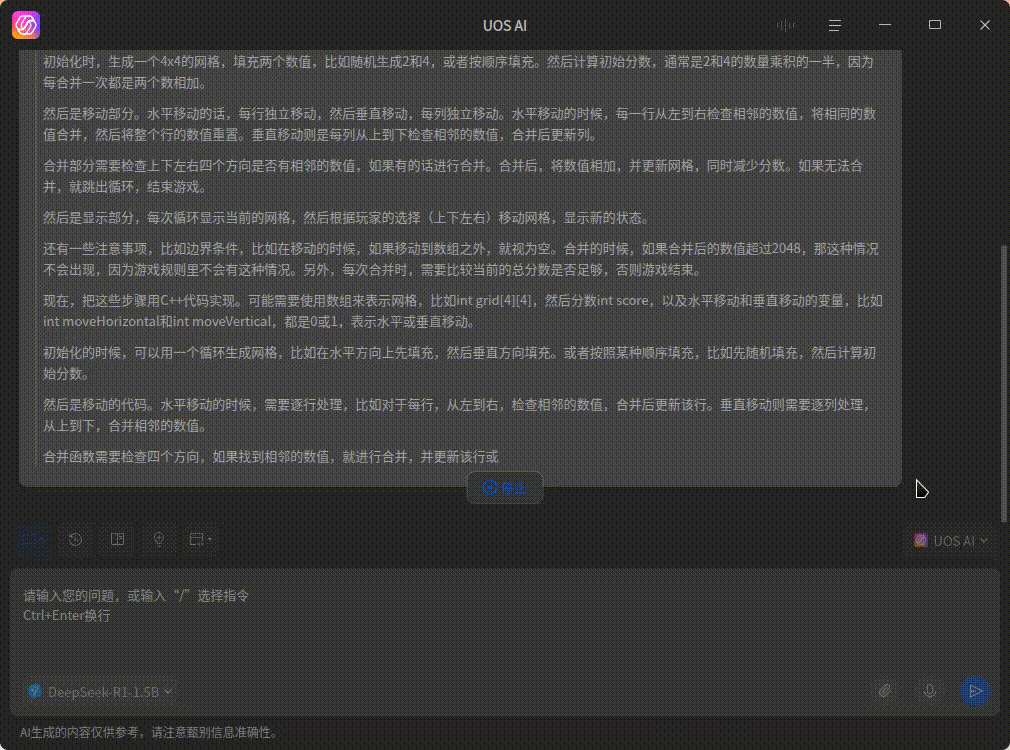
注:本地跑模型对显存的要求比较高,我这里跑 DeepSeek 1.5B 模型就需要 2 个多 GB 的显存了,如果显存太小就没什么必要折腾了,爆显存的话还没纯 CPU 计算的快
而且如果你的 n 卡太老或性能太低,可能跑的效果还不如 CPU 算的快
然后需要安装 n 卡闭源驱动才能用,开源驱动用不了哈

下载链接:https://gfdgdxi.lanzouw.com/b0pnixtti
密码:9msn

